This is part one in a series of blog posts for my ‘IT Professional Skills’ module
Throughout this series of four blog posts, I’ll be providing a basic overview of the concept of binary trees as well as writing a small demo in C to more concretely illustrate the concepts I’ll be discussing.
A binary tree is an example of a computer science data structure. More plainly, a binary tree is a way to store and access data that is computationally efficient. Binary trees are so-called because, when visualised, their structure resembles a tree with interconnected branches sprouting from a single root:
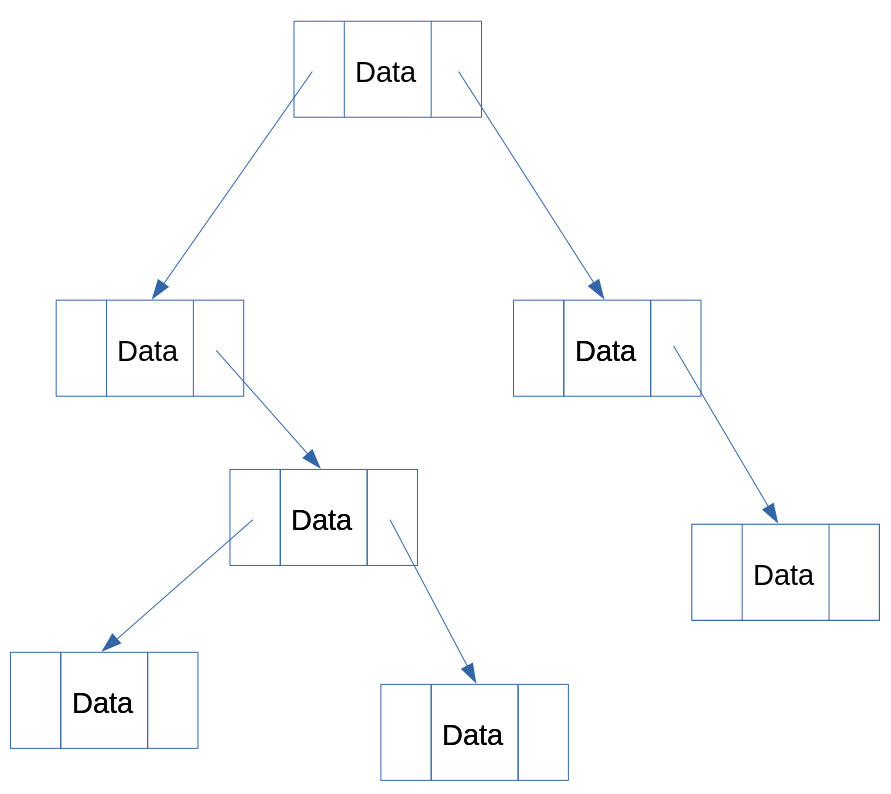
The above diagram is a simple visualisation of a binary tree. Each box represents what’s called a node. In turn, each node is comprised of three parts:
- Some type of data
- A pointer to the next node on the left
- A pointer to the next node on the right
To understand the ideas and code that I’ll be later discussing, it’s important
to get a grasp of what’s known in C as a struct. In C, a struct is a
user-defined data structure that groups different pieces of data in a logical
way. For example, a C struct that describes a point on a plane could be:
struct point
{
int x;
int y;
};
The above code snippet declares a struct called point that has two members:
x and y. Later, when I want to use my creation in a program, I can create a
struct of type point called p and assign values to x and y. Like so:
struct point p;
p.x = 4;
p.y = 2;
Using the same syntax, I can declare a node for my binary tree:
struct node
{
char *data;
struct node *left;
struct node *right;
};
What values could I give to the members of this struct? In this case, data
could point to a string containing somebody’s name. However, the interesting
work happens with the other two pointers. As you most likely can infer, left
and right are pointers to two other structs of type node.
I will delve into the implications of this in my next installment.